Secure Data Sync Agent
Context, Goals, and Scope
Maplewood Public Library runs its catalog and patron system on a legacy Windows Server with SQL Server. That database is the only operational copy of the library’s books, patrons, checkouts, fines, and holds. Concourse is building a cloud-hosted patron portal, which needs a bridge to move selected data from the library server into the cloud without risking the library’s day-to-day operations.
The bridge is an outbound sync agent. It runs on the library server, reads from SQL Server locally, encrypts data before it leaves the building, and uploads batches to Concourse over HTTPS. The cloud side stores, validates, audits, and applies those batches into a tenant-specific read model for the portal.
The source SQL Server remains the system of record. The cloud database is a replicated read model. The portal may lag by a few minutes; it must never show corrupted data, apply changes out of order, or mix one patron’s data with another’s.
The design assumes read-only access to the source database. It requires no inbound network access, VPN, port forwarding, database triggers, schema changes, Docker, or runtime install on the library server. Payment events created in the cloud fall outside the agent’s write path; reconciliation back to the legacy system is a separate workflow.
The architecture is designed to scale from Maplewood to larger library systems through batch sizes, polling intervals, worker capacity, and tenant-level configuration, leaving the underlying protocol unchanged.
Architecture Overview
The system has two halves, an on-premises agent and a cloud ingestion pipeline. The agent is deliberately small. It reads from SQL Server, builds encrypted batches, keeps a local durable spool, and uploads them to Concourse. It runs no inbound listener and makes no decisions that depend on how the portal works.
Everything strict happens in the cloud, where the pipeline authenticates the agent, durably stores what it uploads, validates ordering and mapping, decrypts the data, applies it to the portal read model, and records audit events. Keeping these checks in one place gives Concourse a single controlled point to enforce tenant boundaries, replay failed batches, pause unsafe streams, and support a library without anyone asking Dave to debug the server.
Uploaded data lands in object storage before anything touches the application database, and that one extra hop makes retries and outages safe. Once a batch is durably stored, the agent moves on. If processing later fails, Concourse still holds the encrypted batch and can inspect, replay, or quarantine it without reaching back to the library server.
Processing is asynchronous, so the short upload path means unreliable internet never holds open database work or application writes. Workers pull batches from the landing zone, serialize work within each tenant and entity stream, and apply changes idempotently to the read model. When a sequence is missing or a mapping does not match, the affected stream pauses and alerts Concourse rather than guessing.


Components and Responsibilities
| Component | Responsibility |
|---|---|
| SQL Server (source) | System of record. Read-only access, no tables, triggers, or sync state added. |
| Sync Agent (on-prem) | Discovers, reads, encrypts, spools, and uploads batches. No inbound listener, no portal logic. |
| Local State & Spool | Holds watermarks, row hashes, the open-checkout set, sequence numbers, retry state, and encrypted batches. |
| ALB (cloud front door) | Terminates mutual TLS and verifies the client certificate against the Concourse agent CA. |
| Ingestion Service | Authenticates and validates, writes ciphertext to the landing bucket, records receipt audit, returns the acknowledgment. No decryption. |
| S3 — Landing | Durable encrypted batches under a tenant / agent / entity / sequence path. Replay source for failed processing. |
| SQS FIFO | Ordered processing signal per tenant / agent / entity stream, scalable across independent streams. |
| Worker | Decrypts, validates order and mapping, applies idempotent upserts and guarded deletes, records audit. Pauses the stream on error. |
| KMS | Holds the private decrypting key. The agent gets public material only, so it can encrypt but never decrypt. |
| RDS — Read Model | Portal read model on Aurora / RDS Postgres, tenant-partitioned, with processed_batches and sync_stream_state. |
| Audit Store | Queryable Postgres rows plus immutable, hash-linked Object-Lock manifests for the contractual record. |
| Monitoring / Control Plane | Tracks enrollment, revocation, versions, lag, and paused streams. Dave sees a status and a support code. |
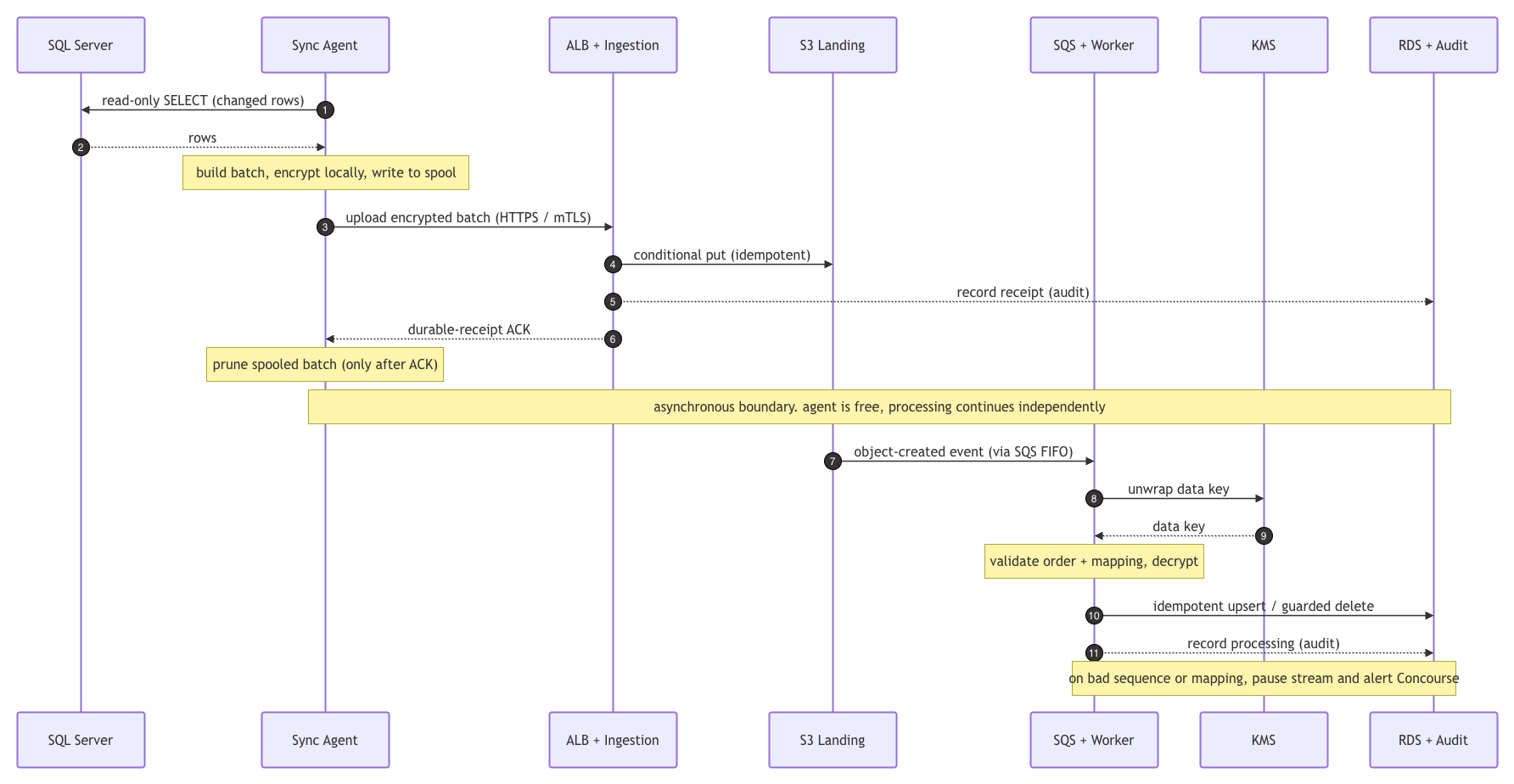
End-to-End Data Flow
Each sync cycle starts on the library server. The agent reads from SQL Server using the approved mapping and the strategy for that entity, where small mutable tables compare against a local row-hash snapshot and Checkouts read new rows by watermark and recheck open checkouts until they return. Those detected changes become a batch tagged with one tenant, agent, entity, and sequence number, plus metadata for mapping version, row count, source watermark, and a content hash. The sequence number and batch are written to the local spool in one transaction, so a crash cannot leave an allocated sequence with no batch behind it.
Encryption happens before anything leaves the building. The agent creates a per-batch data key in memory, encrypts the payload, and wraps that key with Concourse’s public encryption material, while the decrypting private key never sits on the library server. Upload then goes out over HTTPS using the agent’s client certificate, and the ingestion service checks identity, tenant binding, revocation, metadata, batch id, and content hash. A batch it has not seen gets written to the landing bucket with a receipt-audit record, while a batch it has already stored returns the same acknowledgment, which makes a retried upload harmless.
That acknowledgment means Concourse has durably received the encrypted batch. It does not mean the portal database has applied it. Only after the acknowledgment does the agent mark the spool entry done and prune it past a short retention window.
Once a batch lands, a FIFO queue message points workers to the stored object, ordered within each tenant, agent, and entity stream. A worker loads the object, unwraps the batch key through KMS, decrypts the payload, validates the mapping version and shape, and confirms it is applying the next expected sequence. Valid batches go to the Postgres read model as idempotent upserts and guarded deletes, recorded in processed_batches with sync_stream_state updated and processing audit written. A failed validation, a wrong mapping version, or a missing sequence pauses the affected stream and alerts Concourse.
The result is at-least-once delivery from the agent and exactly-once effect in the cloud. The agent retries uploads safely, Concourse replays accepted batches from object storage, and the portal database changes only through validated, ordered, idempotent processing.

Security and Credential Model
The model keeps two concerns separate. One proves which agent is uploading. The other encrypts the data so only Concourse can read it. The agent needs an identity credential to send data unattended, and it never holds a persistent or cloud-decrypting key for synced library data. Its only encryption key is an ephemeral per-batch key held in process memory, discarded once the batch is encrypted and wrapped.
Enrollment establishes that identity. Concourse issues a short-lived code for a specific library, Dave enters it in the setup wizard, and the agent generates a keypair locally and sends a certificate signing request. Concourse returns a signed client certificate plus initial configuration, and because the private key is created on the library server, it never leaves it. That certificate becomes the agent’s upload identity. Future uploads use mutual TLS, the ingestion service maps the presented certificate to a specific agent_id and tenant_id, and revocation is checked in the control plane on every request, so a compromised or retired agent is disabled immediately rather than at certificate expiry. The flow is idempotent within the code window, so a lost response lets the same key fingerprint retry and receive the same certificate, while a different keypair claiming an already-used code is rejected.
The private key prefers the Windows machine certificate store marked non-exportable, with a DPAPI-protected local file as the fallback. That fallback stops the credential from being copied to another machine, though not from malicious code already running with enough privilege on the server. Certificates rotate before expiry, with the agent renewing through its current certificate, generating a fresh local keypair, and receiving a replacement. After a long outage, Concourse can let a recently expired certificate reach only the renewal endpoint for a short grace period, provided the agent has not been revoked, and that grace path cannot upload data.
Data protection uses envelope encryption, already shown in the batch flow above. For each batch the agent creates a data key in memory, encrypts the payload, and wraps the data key with public material from Concourse, while the decrypting private key stays in cloud KMS or an HSM-backed equivalent. Public material can live on the agent safely, since it only allows encryption toward Concourse and never decryption, so the spool holds nothing but ciphertext that an outage simply leaves on disk for later retry. In the cloud, the landing bucket, read model, and audit store all use provider encryption at rest, which layers on top of payloads that were already encrypted before leaving the library.
This bounds the blast radius. A stolen agent credential mainly buys impersonation, an attempt to inject new uploads, and cannot decrypt historical batches stored locally or in the cloud. The cloud contains even that through tenant binding, metadata validation, batch sequencing, delete guardrails, anomaly detection, and revocation.
Schema Discovery and Mapping
The entity types are known, but the exact schema is not, and the agent should never guess the production meaning of arbitrary columns on its own. It can inspect the database, yet Concourse approves the mapping before the agent treats any data as production sync input. During setup, the agent runs a discovery probe using the same read-only SQL credentials it will use for sync. The probe lists visible tables, columns, data types, row counts, keys, indexes, candidate timestamp and rowversion columns, and likely entity matches, which also confirms the supplied SQL account can actually read the tables it needs.
The discovery output becomes a mapping reviewed by Concourse. That mapping identifies which table backs each entity, which column or columns form the stable key, and which business columns are replicated. It also marks special fields such as returned_date for Checkouts, soft-delete indicators where present, and any timestamp or version column safe to use as an optimization.
A stable key is required. Without a primary key or confirmed natural key, the agent cannot reliably tell an update from a delete-plus-insert, and delete detection becomes unsafe. When no stable key exists for a required table, onboarding pauses for Concourse to resolve the mapping rather than letting the agent guess.
Row hashing covers only the mapped business columns, which avoids noisy diffs from volatile metadata, computed columns, or fields irrelevant to the portal, and limits what the agent reads and sends to what the cloud actually needs. Mappings are versioned, and each batch carries the version used to produce it. A worker that receives a batch for an unexpected mapping version pauses that entity stream and alerts Concourse rather than reinterpreting the payload.
Sync Strategy, Ordering, and Idempotency
The sync strategy is chosen per table, so the design never depends on one universal change-detection feature being present in the legacy database. The agent polls on a schedule and batches the changes it finds, rather than uploading once per row change. A reasonable default is every one to five minutes for patron-facing entities such as checkouts, holds, patrons, and fines, with catalog data on a slower hourly or adaptive cadence. If a poll finds more changes than one batch should carry, the agent splits them into bounded chunks.
Books, Patrons, Fines, and Holds are small mutable tables, so the agent uses full snapshot plus keyed row-hash diff. On each interval it reads the mapped business columns, computes hashes by stable key, and compares them to the last local snapshot, where new keys become inserts, changed hashes become updates, and missing keys become deletes. This stays simpler and safer than trusting an unknown timestamp column, and at Maplewood’s size the query cost is tiny.
Checkouts are handled differently because that table grows over time. New rows are detected with a monotonic primary key or rowversion when one exists, and the one expected mutation, returned_date changing from null to set, is handled by tracking the open-checkout set and rechecking those rows until they close. This avoids scanning all historical checkouts and avoids missing a long-overdue return that falls outside a fixed time window. If discovery shows that returned rows can mutate in other ways, the strategy adds a bounded timestamp or recent-key rescan as a supplement, though the base assumption follows the prompt, where Checkouts are append-heavy and returned_date is set once.
The first sync is a full seed produced in bounded batches, after which each entity follows its incremental strategy. If the agent loses local hash or watermark state, it reseeds and re-emits the affected data, and cloud-side idempotency makes that a recovery path rather than a duplicate-data problem. Every batch belongs to one tenant, agent, entity, and sequence number, and the batch id is position-based on those fields while the content hash stays separate as an integrity check. A repeat of the same id and hash returns the same acknowledgment, while the same id with a different hash is quarantined as a bug or tampering signal.
Sequence allocation and spool write happen in one local transaction, so a crash before commit leaves the sequence unallocated and a crash after commit leaves a durable batch that will be retried. This keeps the cloud from waiting on a sequence the agent only half-created. Processing is then ordered per entity stream, with the queue keyed on tenant, agent, and entity so workers scale across libraries and entities while preserving order inside one stream. A missing sequence pauses that stream and alerts Concourse.
Application is idempotent. Workers record processed batch ids, use upserts for inserts and updates, and apply deletes through guardrails, where a delete batch that would remove an unusual share of a table is quarantined rather than blindly applied, since a partial read should not wipe the portal’s read model. The overall model is at-least-once delivery from the agent and exactly-once effect in the cloud, where the agent retries freely and the cloud owns dedupe, ordering, validation, and safe application.
Audit Trail
Every sync operation leaves a permanent record of what happened, who or what performed it, when, and how it ended. The trail records both successes and failures, because a failed validation, paused stream, or rejected batch is often the event that matters most later.
Queryable audit lives in Postgres as append-only rows, restricted through the application and database roles. Each row holds metadata for tenant id, agent id, event type, entity, batch id, sequence number, mapping version, timestamp, actor or service, status, row counts, content hash, source watermark when relevant, and error code, and it avoids raw patron PII.
Permanent audit lives in a separate Object-Lock store. Periodic manifests are written there with hashes linking each to the previous one, giving Concourse a tamper-evident record stronger than the operational table. A database administrator could alter ordinary Postgres rows, yet those changes stay detectable against the locked manifests.
The model is intentionally simple. Postgres gives support a practical way to answer what happened to a batch or why a stream paused, while Object-Lock manifests and hash links carry the contractual permanence requirement without a separate ledger system.
Deployment and Operations
The operator experience is wizard-first. Dave never needs a CLI, configuration files, logs, sync tuning, or any understanding of certificates. The single distributable artifact is one signed Windows .exe that acts as installer, setup wizard, and service executable in different modes. Double-clicking it launches the wizard, and after setup the same binary runs as a Windows service, with no Docker, no runtime install, and no installer that downloads packages.
The wizard asks only for fields Dave can reasonably provide, namely the SQL Server host, database name, authentication method, SQL credentials or Windows authentication choice, and the Concourse enrollment code. The database test connects, authenticates, verifies read permission, and runs the discovery probe so permission problems surface during setup. It also tests cloud reachability and enrollment, and if the internet drops after Concourse signs the certificate but before the response arrives, the same attempt retries safely because enrollment is idempotent for one key fingerprint.
When setup succeeds, the binary installs and starts the Windows service. Local status stays simple, showing healthy, syncing, waiting for Concourse setup, or needs support, and the service can sit in a waiting state while Concourse finishes approving the mapping. If something fails beyond Dave’s reach, the UI shows a short support code that he relays to Concourse, which maps it to the real diagnostic in the control plane. Dave is a human relay for a support token, never a debugger.
Day to day, the service starts on boot, retries automatically, spools through internet outages, renews credentials, and sends heartbeats. Logs can go to the Windows Event Log and a rotating local diagnostic file for Concourse support, while the local UI never requires Dave to inspect them.
Updates are manual in the first version. Concourse sees agent version in the heartbeat, detects drift, and tells Dave when to run a replacement signed binary. Managed auto-update can come later, and the base design does not require it.
Scaling and Performance
The design scales by keeping the agent conservative and moving heavier work to the cloud. On the library server, reads are bounded by batch size, query timeout, concurrency limit, and backoff, and the agent prefers short read-only queries over long transactions, slowing down if queries exceed limits or the local spool grows too large. Batches are processed in bounded, streamed chunks rather than loaded whole, so memory stays flat regardless of table size. The spool has a disk budget, so a long internet outage keeps encrypted batches only up to that budget, reports queue growth through heartbeats, and backs off before it risks filling the server disk.
Per-table strategies carry their own headroom. Small tables keep snapshot-diff while they stay small, and a future library with a much larger patron or catalog table can graduate it to a watermark or timestamp strategy after mapping review. Checkouts scale through an indexed watermark for new rows and open-checkout polling for returns, so the hot path never scans the whole history every few minutes, while infrequent primary-key reconciliation catches rare hard deletes without that cost on every cycle.
In the cloud, storage is partitioned by tenant, agent, entity, and sequence or date. SQS FIFO serializes work inside one entity stream while allowing parallel work across others, so a paused Holds stream for one tenant does not block Checkouts for another. Workers scale horizontally across streams, KMS work is bounded to one unwrap per batch rather than one per row, and Postgres holds processed_batches and sync_stream_state so retries and duplicate queue messages create no duplicate effects.
The main tradeoff is freshness versus production safety. The system prefers a slightly older but correct portal over aggressive polling that risks the only copy of the library’s operational database. Freshness targets, batch sizes, and polling intervals are tenant and entity configuration, leaving the protocol unchanged.
Scope Boundaries
This design covers outbound replication from the library’s SQL Server into a Concourse-operated cloud read model. It requires no inbound connectivity, VPN, port forwarding, or direct cloud access to the library database. Several things sit deliberately outside that boundary.
There is no write-back to the legacy system. Online payment events can be stored in the cloud application database, but reconciling them into the library’s legacy software is a separate workflow with its own failure modes and approval requirements.
No source database changes are needed. The agent can use existing change metadata such as rowversion, timestamps, or SQL Server Change Tracking where they already exist, without enabling features, adding triggers, or creating sync tables in production.
Fully automatic understanding of arbitrary legacy schemas is out of scope. The agent discovers and proposes, and Concourse approves the mapping before sync becomes authoritative. Managed auto-update is also out of scope for the first version, where a signed manual replacement binary is enough for the pilot and version drift stays visible to Concourse through heartbeats.
Risk Register
The risks below are ranked by severity, taken as impact multiplied by likelihood. Each maps to a constraint in the brief and to a mitigation already built into the design.
| Rank | Risk | Severity | Why It Matters | Mitigation |
|---|---|---|---|---|
| 1 | Agent harms production SQL Server | Critical | The only operational copy; locks or resource pressure could stop checkouts. | Read-only, bounded batches, timeouts, low concurrency, backoff, disk budget. |
| 2 | Data lost or duplicated on network failure | Critical | The modem is unreliable; retries must not corrupt the portal. | Durable spool, atomic batch+sequence write, idempotent cloud, replayable ack. |
| 3 | Encryption or credential model compromised | Critical | Patron PII must stay encrypted, with no decrypt key on-prem. | Envelope encryption, private key in KMS, mTLS auth, non-exportable storage, revocation. |
| 4 | Wrong schema mapping syncs wrong data | High | The legacy schema is unknown; a bad mapping mixes or misses fields. | Concourse-approved mapping, required stable keys, versioned mappings, pause on mismatch. |
| 5 | Changes missed from weak change metadata | High | Legacy tables may lack reliable timestamps or rowversion. | Per-table strategy, snapshot diff, open-checkout tracking, reseed, reconciliation. |
| 6 | Delete detection removes too much | High | A partial read could look like many rows vanished. | Mass-delete thresholds, quarantine, audit, Concourse resolution before applying. |
| 7 | Poison batch or sequence gap blocks a stream | High | A bad batch could stall a stream and leave the portal stale. | Per-entity ordering, dead-letter + stream pause, alerting, replay from storage. |
| 8 | Audit trail incomplete or not defensible | High | The contract requires permanent, immutable sync records. | Append-only rows, Object-Lock hash-linked manifests, metadata not PII, success and failure. |
| 9 | Dave cannot install or recover the agent | Medium | A non-technical operator cannot debug logs or edit config. | Self-installing .exe, wizard setup, real tests, simple status, support-code escalation. |
| 10 | Larger tenants exceed pilot assumptions | Medium | The design must scale beyond Maplewood. | Tenant partitioning, worker scaling, indexed watermarks, configurable intervals, lag monitoring. |