Autoresearch for Earth System Models
Inspired in part by Karpathy’s autoresearch framework for LLM-driven scientific discovery, we apply the idea to a domain where the formulas are grounded in physics and the observations are global. Earth system models simulate plant growth, fire, soil carbon cycling, and water fluxes globally. They contain hundreds of parameterized formulas governing these processes, many of which have remained structurally unchanged since their original publications in the 1980s and 1990s. Tuning the parameters of these formulas is the standard approach to model improvement, and it assumes the underlying equation is correct. In this work, we describe an autoresearch methodology that uses LLMs to systematically evaluate whether the formula structure itself should be replaced, searching the joint space of equations and parameters against observational benchmarks, and maintaining physical interpretability throughout.
We applied this methodology to the Ecosystem Demography model (ED v3.0)
Physical Grounding as a Design Constraint
Every formula proposed by the autoresearch system must correspond to a named physical process with published justification. Lloyd-Taylor
The LLM serves as a diagnostic engine, drawing on the ecological and biogeochemical literature to identify structural mismatches between model assumptions and observed spatial patterns. All formulas are expressed in basic arithmetic operations (exponential, logarithm, power, conditionals) and must be portable to the model’s native C++ implementation. This constraint excludes neural networks, learned embeddings, and any representation that cannot be interpreted in terms of a physical mechanism.
The Autoresearch Loop
The methodology follows a systematic cycle applied to each model module. The parameterized formula is extracted from the model’s C++ source and replicated in Python, enabling fast evaluation over the global 0.5° grid (~1 second per evaluation). The Python replica is compared against gridded observational datasets (HWSD for soil carbon, GLEAM for evapotranspiration, GFED for burned area, FLUXCOM for gross primary productivity, MODIS for leaf area index, LORA for runoff). The LLM then diagnoses why the model disagrees with observations, drawing on physical reasoning to propose structural alternatives organized along defined axes.
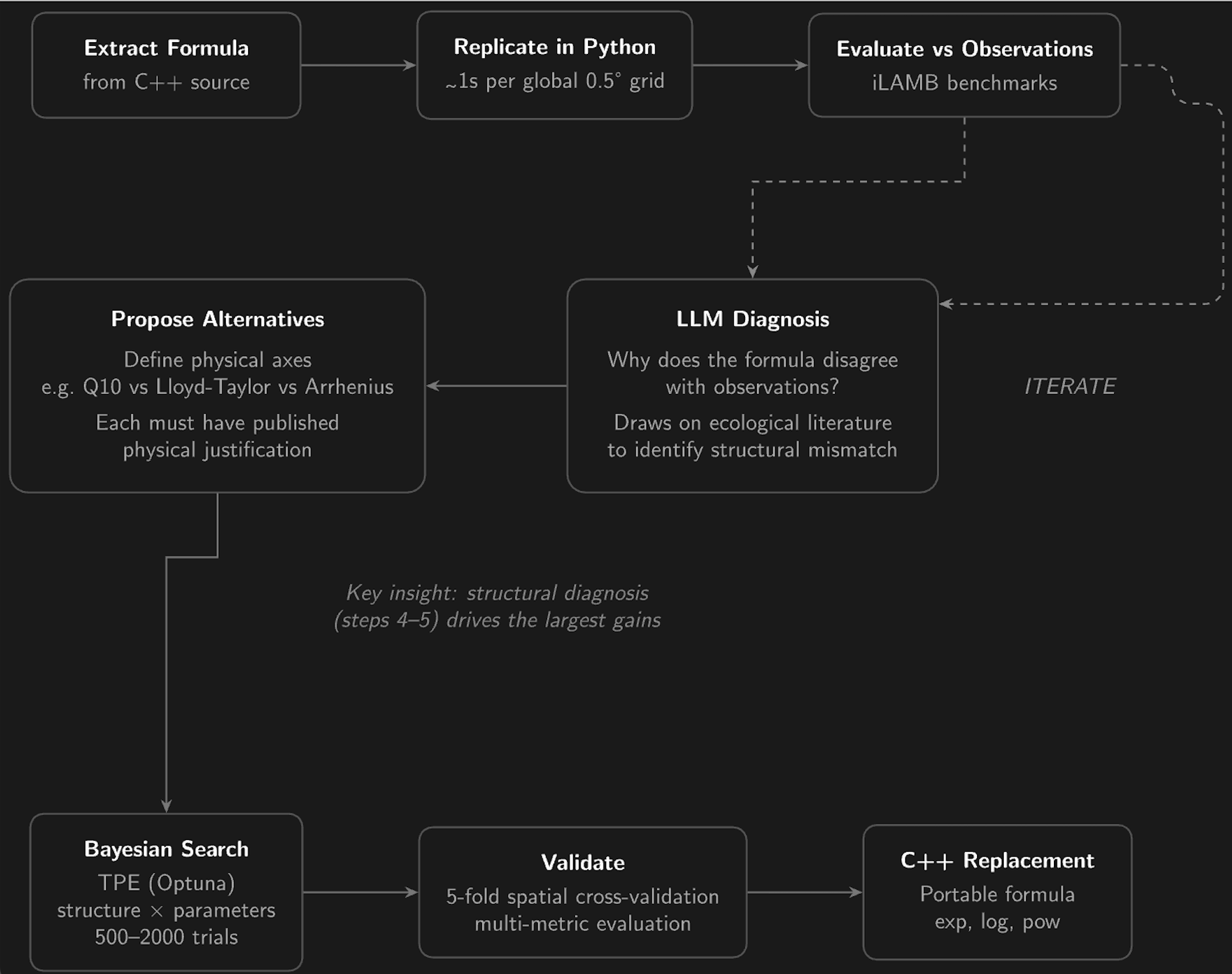
Each axis represents a dimension of the formula’s physical assumptions. For soil carbon decomposition, the axes include: (1) the temperature response function (Q10 vs. Lloyd-Taylor vs. Arrhenius vs. bell-curve), (2) the moisture response function (piecewise linear vs. log-parabolic vs. Michaelis-Menten with anaerobic suppression), (3) the pool structure (4-pool CENTURY vs. 3-pool vs. 2-pool), and (4) additional input variables (vegetation cover effects on soil temperature). Each alternative on each axis corresponds to a published model or physical mechanism.
The search over this combinatorial space of structures, combined with continuous parameter optimization within each structure, is performed using Bayesian optimization. Specifically, we use the Tree-structured Parzen Estimator (TPE)
Each module receives a tailored multi-metric objective function reflecting what matters ecologically. Spatial correlation alone is insufficient. For hydrology, the objective includes water balance closure (precipitation must equal evapotranspiration plus runoff). For soil carbon, both stock accuracy (against HWSD) and flux accuracy (against Hashimoto et al.
Following the Dependency Graph
The modules in ED form a directed dependency graph. Climate forcing drives photosynthesis, which feeds growth and hydrology. Hydrology governs soil moisture, which feeds back to phenology and soil carbon decomposition. Litter from growth and mortality enters the soil carbon pools. Fire is downstream of all other processes, depending on fuel load (biomass), fuel moisture (dryness), and seasonal productivity (GPP).
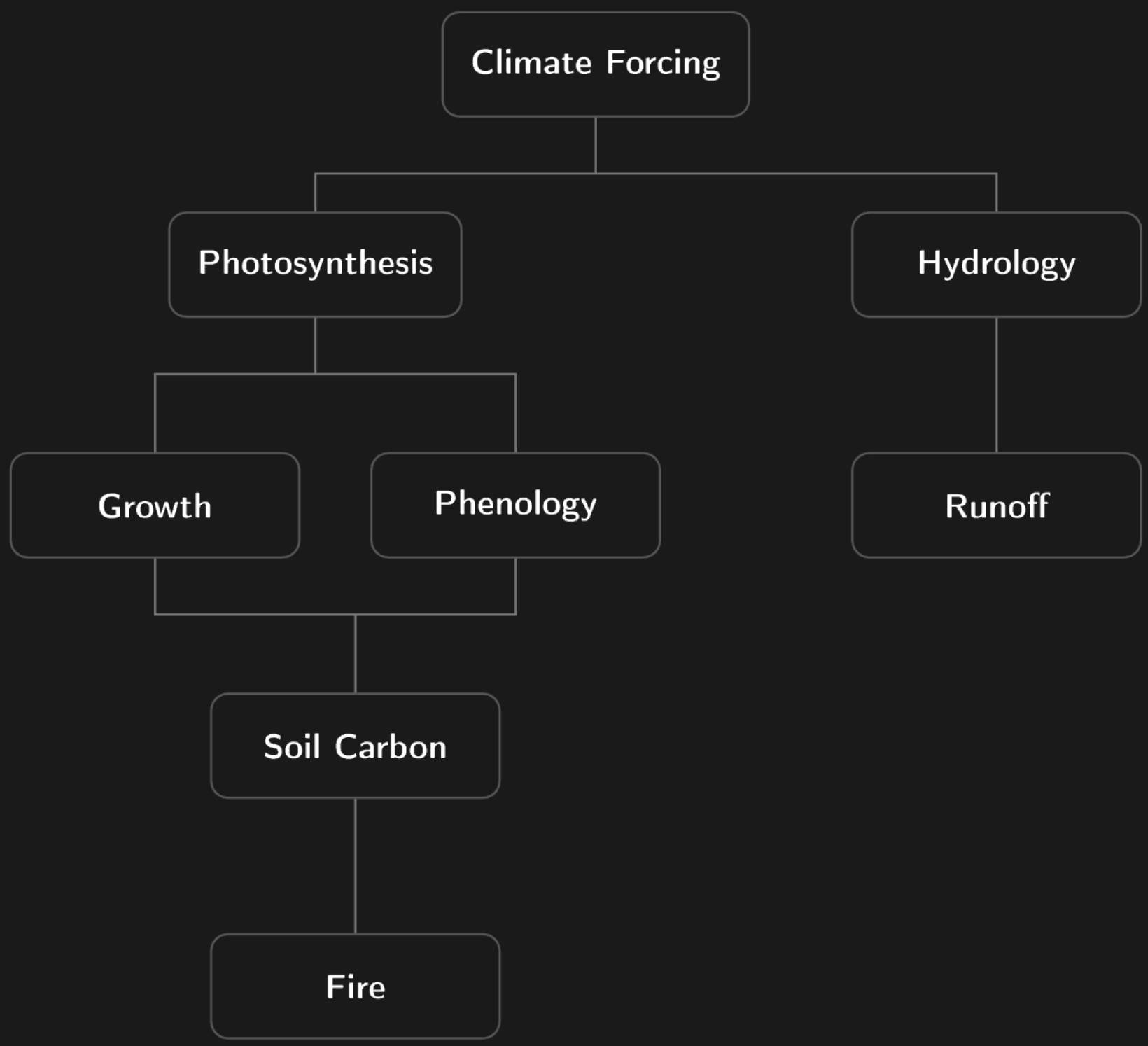
This dependency structure determined our optimization order and revealed constraints that single-module optimization would miss. An improvement to the photosynthesis module cascades to better litter input estimates, which in turn affect soil carbon predictions. Evapotranspiration and runoff share water balance as a conservation law: they cannot be optimized independently without risking physical inconsistency. We return to this cross-module consistency problem in a later section.
Fire and the Intermediate Productivity Hypothesis
The fire module provided the initial proof of concept for the autoresearch methodology. ED’s original fire formula computed burned area as a power-law function of above-ground biomass and a dryness index:
\[\text{fire} = \text{AGB} \times \left(\frac{\bar{D}}{\text{norm}}\right)^{\text{exp}}\]This formulation assumes that fire risk increases monotonically with fuel load and dryness. Evaluation against GFED4.1s burned area
The LLM diagnosis identified a well-documented ecological pattern that the formula structure fails to capture: fire occurrence peaks at intermediate levels of productivity
The replacement formula couples a sigmoid ignition function with a unimodal fuel response:
\[\text{fire} = \frac{1}{1 + e^{-k(\bar{D} - D_0)}} \times \left(1 - e^{-\text{AGB}/b}\right) e^{-\text{AGB}/d}\]The sigmoid captures the threshold behavior of fuel curing (a smooth transition from non-flammable to flammable as dryness accumulates). The hump-shaped fuel term peaks at intermediate biomass, consistent with the savanna fire regime. Spatial correlation improved to r = 0.41.
Incorporating GPP as a third input further improved the model to r = 0.65. GPP captures the seasonal productivity cycle through its linkage to stomatal conductance: high GPP during the growing season indicates active transpiration and fuel production, while subsequent dry-season GPP decline indicates fuel curing. For reference, published global fire models in the TRENDY ensemble typically achieve r = 0.5-0.7 against GFED.
\[\text{fire} = \text{sigmoid}(\bar{D}) \times \text{fuel_hump}(\text{AGB}) \times \text{productivity_hump}(\text{GPP})\]This structural change, from a monotonic to a unimodal response, was the primary source of improvement. Parameter tuning within the original power-law structure yielded negligible gains.
Decomposition and the Cold Soil Problem
ED’s soil carbon decomposition follows a simplified CENTURY model
The constants \(R_0 = 0.40\), \(Q_{10} = 1.5\), and the moisture breakpoints are hardcoded in the C++ source. They have never been tuned against observational soil carbon datasets.
The Q10 formulation assumes a fixed proportional increase in decomposition rate per 10°C warming. At low temperatures, this produces an exponentially declining curve that approaches zero at 0°C. Davidson and Janssens
{
"tooltip": {"trigger": "axis"},
"legend": {"data": ["Q10 (original)", "Lloyd-Taylor (1994)"], "top": "5%"},
"xAxis": {"type": "category", "name": "Temperature (°C)", "nameLocation": "center", "nameGap": 30, "data": ["-20","-15","-10","-5","0","5","10","15","20","25","30","35","40","45"]},
"yAxis": {"type": "value", "name": "Decomposition rate", "nameLocation": "center", "nameGap": 40, "max": 1.0},
"series": [
{"name": "Q10 (original)", "type": "line", "smooth": true, "lineStyle": {"type": "dashed", "width": 2}, "data": [0,0,0,0,0,0.07,0.10,0.14,0.20,0.28,0.40,0.57,0.80,1.00], "itemStyle": {"color": "#e74c3c"}},
{"name": "Lloyd-Taylor (1994)", "type": "line", "smooth": true, "lineStyle": {"width": 2}, "data": [0,0,0,0,0,0.03,0.05,0.09,0.15,0.24,0.38,0.58,0.84,1.00], "itemStyle": {"color": "#3498db"}}
],
"grid": {"left": "12%", "right": "5%", "bottom": "15%"}
}
The key difference is visible in the 0-10°C range: Lloyd-Taylor rises more gradually from freezing, allowing cold soils to retain more carbon. This matches the observed pattern where boreal and arctic soils contain disproportionately large carbon stocks relative to their low temperatures.
Replacing Q10 with Lloyd-Taylor improved soil carbon predictions at high latitudes, where the original formulation allowed decomposition rates that were too high relative to the cold temperatures. We also replaced the piecewise-linear moisture response with a log-parabolic function
The optimized moisture parameter \(\sigma = 3.7\) is very wide, indicating that moisture has a weak spatial modulating effect on decomposition at the global scale. Temperature dominates. This is consistent with the global synthesis of Bond-Lamberty and Thomson
We further simplified the four-pool CENTURY structure to a two-pool model (labile and stable carbon). The four-pool structure includes a passive pool that in ED is completely inert (decay rate K4 = 0, respiration fraction r = 0), meaning carbon enters but never leaves. Observational datasets (HWSD, NCSCD) report total soil carbon stocks and cannot constrain individual pool fractions. The two-pool structure avoids overfitting while representing the essential distinction between rapidly cycling litter carbon (turnover ~600 days) and slowly cycling humus (turnover ~115 years).
The global soil carbon bias decreased from −50% to effectively zero. Spatial correlation against HWSD improved from 0.43 to 0.48. At high latitudes, correlation against the Northern Circumpolar Soil Carbon Database (NCSCD)
Closing the Water Balance
Evapotranspiration, runoff, and precipitation must satisfy a conservation law:
\[P = ET + R + \Delta S\]At the annual timescale, changes in storage (\(\Delta S\)) are approximately zero, so precipitation should equal evapotranspiration plus runoff. When ET and runoff are optimized against their respective observational targets (GLEAM and LORA) using independently chosen formulations, this constraint can be violated. We found an 81 mm/yr global residual when using separately optimized models.
Joint optimization using a single ET formulation for both targets resolved this. We replaced ED’s hourly Penman-Monteith scheme with the Hargreaves PET estimate
The parameter \(w\) controls the vegetation dependency. A higher \(w\) means a larger fraction of precipitation is returned to the atmosphere through transpiration, reflecting the deeper rooting depth and higher canopy conductance of forests compared to grasslands. The optimized value \(w = 5.2\) indicates strong vegetation control on the water balance. Canopy transpiration exceeds bare-soil evaporation by approximately 44% at the same atmospheric demand, consistent with eddy-covariance observations across biome gradients.
The joint optimization reduced the water balance residual from −81 to −3 mm/yr while maintaining ET correlation at r = 0.93 (against GLEAM) and runoff correlation at r = 0.83 (against LORA).
The Vegetation Coverage Gap
Systematic evaluation across all modules revealed an unexpected finding: 22% of land cells where MODIS observes vegetation and HWSD reports soil carbon, the model initializes no vegetation. These cells are primarily high-latitude tundra and sparse boreal regions (50% of gap cells lie above 60°N, with mean annual temperature of −4.7°C). MODIS confirms real vegetation in these cells, with mean LAI of 0.34.
This gap propagates through the entire dependency graph. Absent vegetation means zero litter input to the soil carbon module, zero transpiration in the hydrology module, and zero fuel for the fire module. It represents 19% of global soil carbon stocks as reported by HWSD, a substantial fraction rendered invisible to the model.
We addressed this with a climate-based gap-fill model. For GPP, we used a light-use efficiency formulation
This finding illustrates a benefit of the autoresearch framework that extends beyond formula optimization. By forcing systematic evaluation of every module against gridded observations, systemic issues that span multiple modules become visible. The vegetation coverage gap was identifiable only by examining the intersection of soil carbon, ET, and GPP failures at the same grid cells.
Summary of Ecological Changes
Across the model, the autoresearch methodology produced five structural changes, each representing a revised understanding of how an ecosystem process operates at the global scale.
| Module | Benchmark | Before | After | Change |
|---|---|---|---|---|
| Fire | GFED | 0.09 | 0.65 | +0.56 |
| GPP | FLUXCOM | 0.56 | 0.73 | +0.17 |
| Soil Carbon | HWSD | 0.43 | 0.48 | +0.05 |
| Soil C bias | HWSD | −50% | 0% | Eliminated |
| ET | GLEAM | 0.88 | 0.93 | +0.05 |
| Runoff | LORA | 0.76 | 0.85 | +0.09 |
| Phenology | MODIS | 0.76 | 0.80 | +0.04 |
| Water Balance | P=ET+R | −81 mm/yr | −3 mm/yr | Closed |
| Process | Original Formulation | Replacement | Physical Rationale |
|---|---|---|---|
| Fire disturbance | Power-law (AGB × dryness) | Sigmoid × unimodal hump | Intermediate productivity hypothesis |
| Decomposition temperature | Q10 | Lloyd-Taylor (1994) | Enzyme kinetics flatten near freezing |
| Decomposition moisture | Piecewise linear | Log-parabolic | Smooth optimum, no hard breakpoints |
| Soil carbon pools | 4-pool CENTURY | 2-pool (labile + stable) | Observations cannot constrain 4 pools; passive pool was inert |
| Evapotranspiration | Penman-Monteith (hourly) | Hargreaves + Zhang Budyko | Vegetation-dependent water-energy partitioning |
In every case, the largest gains came from changing the functional form of the equation, informed by ecological reasoning about the physical process, rather than from tuning parameters within the original formulation.
Spatial cross-validation (5-fold, latitude-stratified) confirmed that the improvements generalize across regions: train-test correlation gaps were below 0.10 for 4 of 5 folds in all modules, with parameter counts of 2-11 against 50,000+ observation cells.
Limitations and Generalization
The results presented here are based on steady-state approximations evaluated against gridded observational products. A full validation requires implementing the formula replacements in the coupled C++ model and re-running the simulation, because nonlinear feedbacks between modules may alter the results in ways that our modular optimization does not capture.
The steady-state assumption for soil carbon is particularly questionable at high latitudes, where permafrost soils are demonstrably out of equilibrium and contain vast carbon stocks that accumulated over millennia. The two-pool model cannot represent this legacy carbon without an explicit frozen-carbon mechanism. The boreal GPP problem, where no single formula adequately captures productivity across tropical, temperate, and boreal biomes simultaneously, remains partially addressed through the biome-blended approach but is fundamentally limited by the quality of the climate-based gap-fill at high latitudes.
The methodology itself generalizes to any parameterized model in the geosciences or beyond. The requirements are: (1) a set of parameterized formulas with physical interpretability, (2) gridded observational targets for evaluation, (3) domain literature from which the LLM can draw structural alternatives, and (4) a fast evaluation pathway (~1 second per trial). The deliverable is always interpretable, portable, and physically defensible. The formulas are the hypothesis. The full model re-run is the experiment.